例子
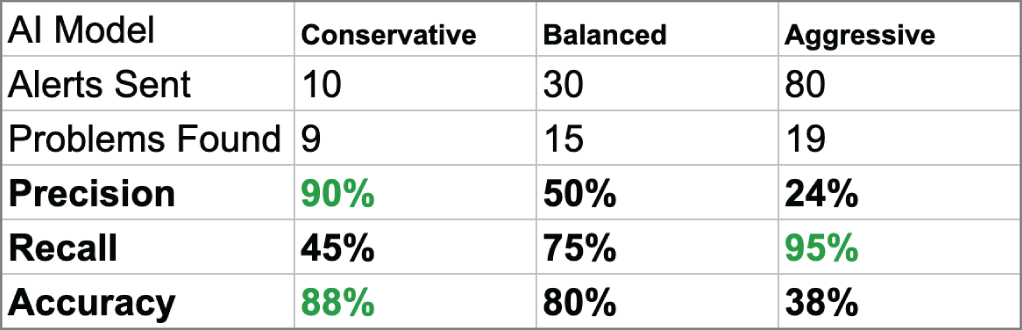
只看 metrics 容易挑到看似漂亮的模型,但它未必符合真實使用情境的風險與成本。
Source in book: Chapter 5
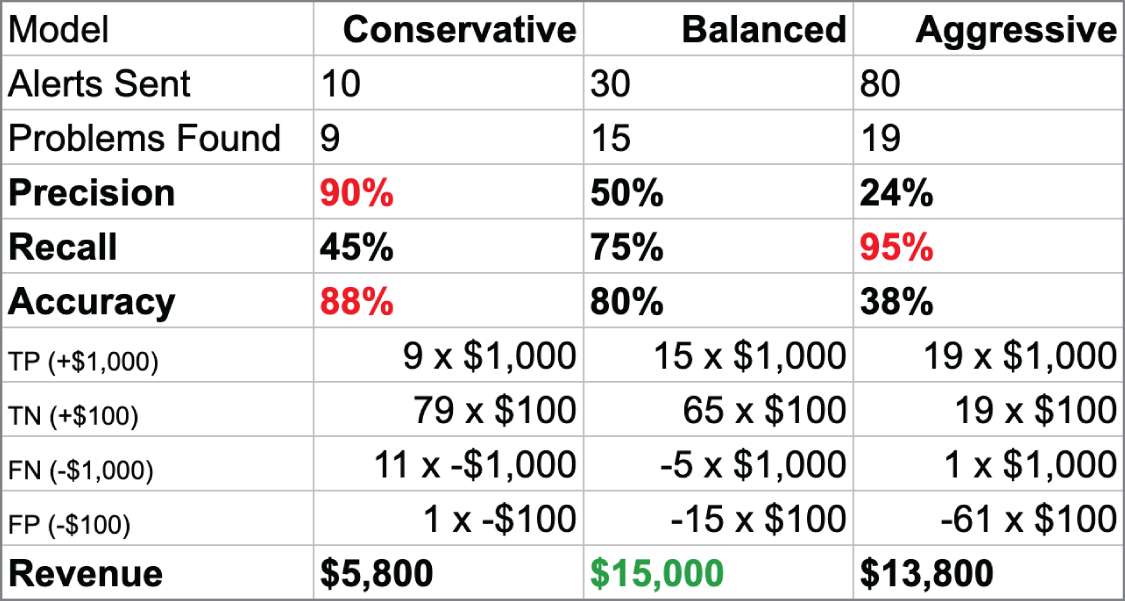
把 outcomes 放進來之後,『哪個模型更好』會變成一個可討論的產品決策。
Source in book: Chapter 5
下面這張圖把 confusion matrix 先用「保守模型」示範一次,幫你把 TP / FP / TN / FN 的計數看懂。
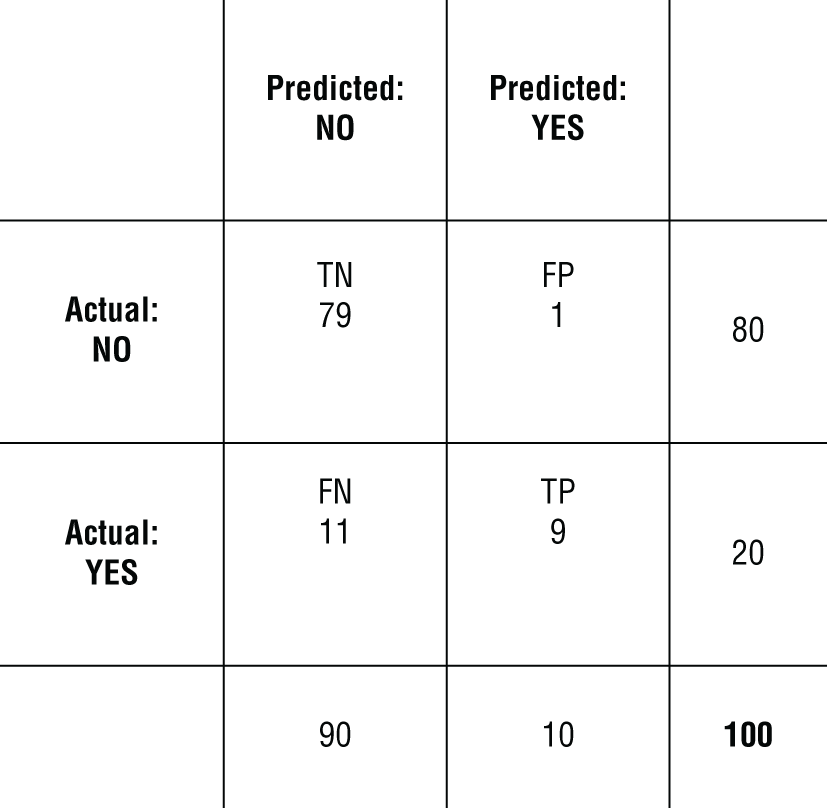
先把四種 outcome 的格子與數量釘住,後面才能把成本/效益貼回去。
Source in book: Chapter 5
圖解(Confusion Matrix 先把事情數清楚)
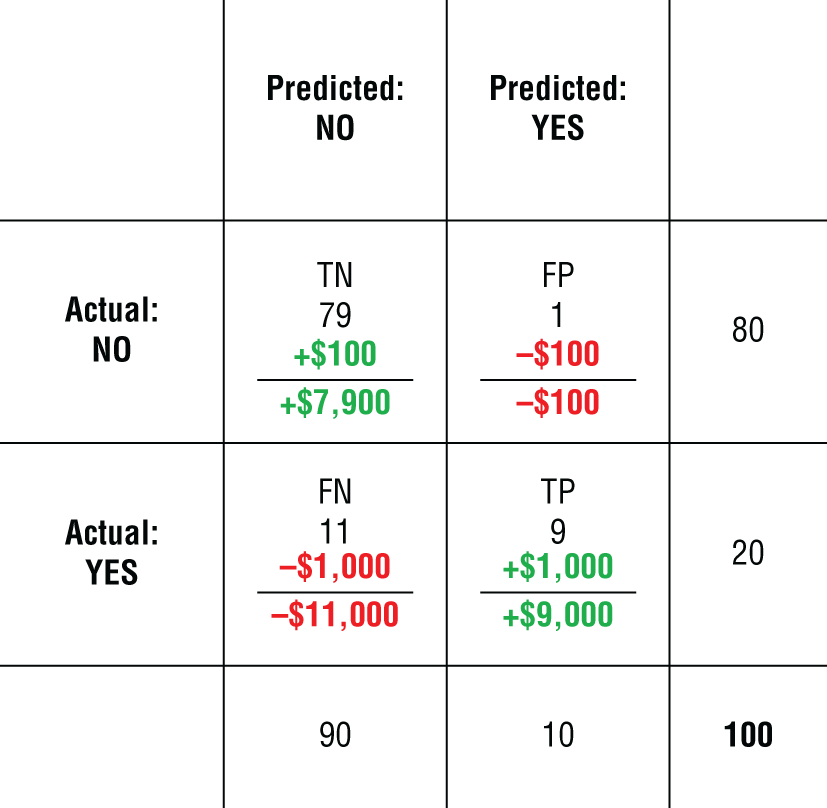
先數清楚四種結果:TP / FP / TN / FN。接下來你才能把成本與效益貼上去。
Source in book: Chapter 5
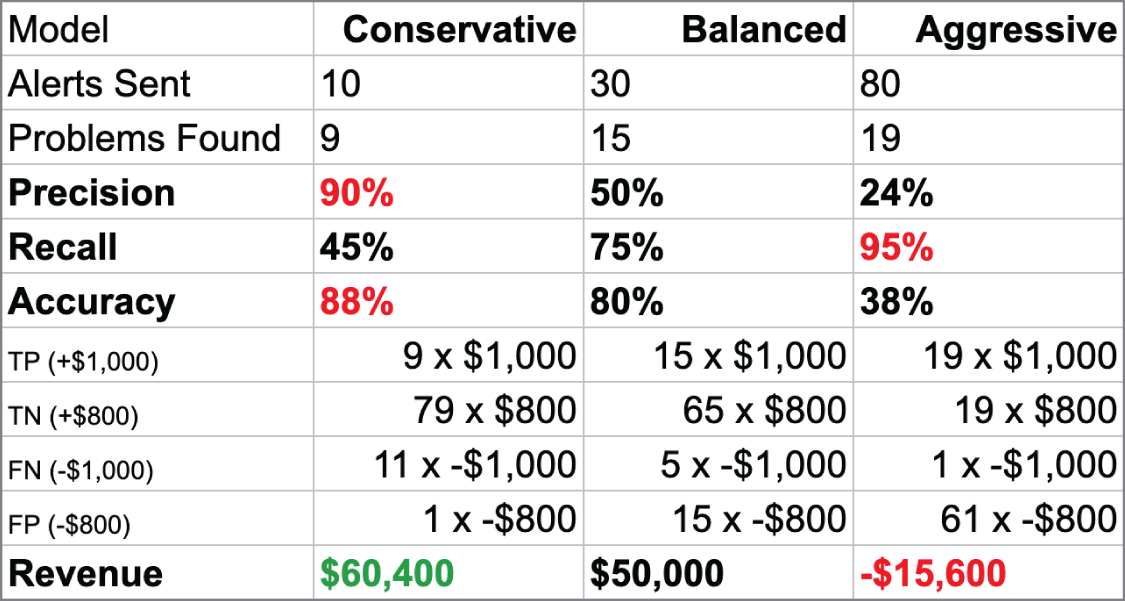
換一組 TN 的價值假設,模型排序就可能翻轉。這一格是把假設變成可討論的地方。
Source in book: Chapter 5
方法(照原書順序:先 outcomes,再 value matrix)
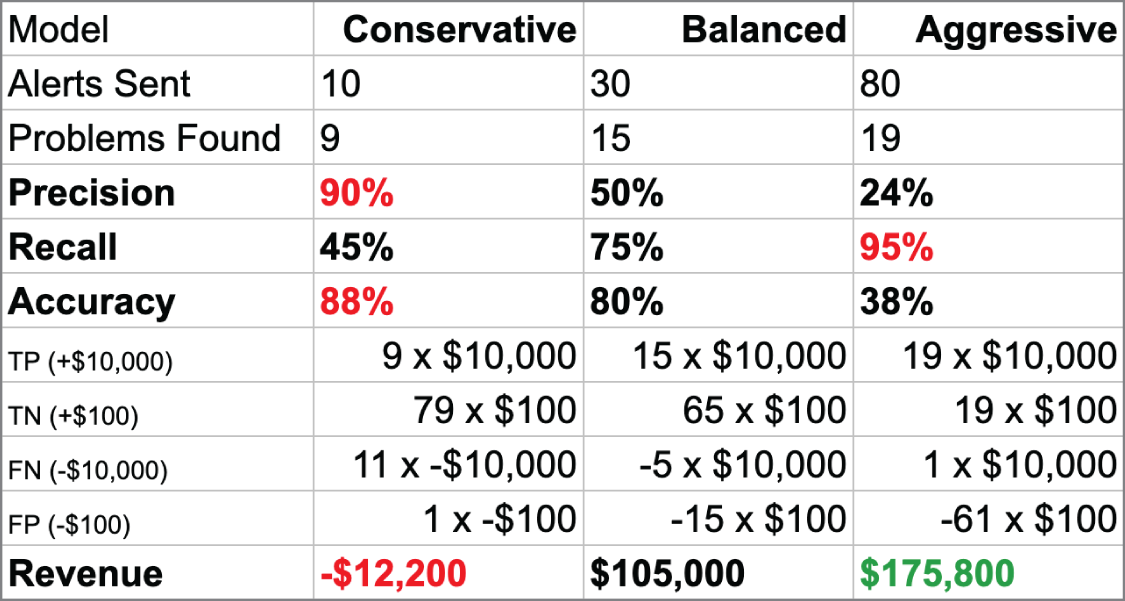
同一個模型,換一組成本/效益假設,結論可能完全不同。這就是為什麼要把 UX 與業務目標放進評估。
Source in book: Chapter 5
如果你要把這一套方法拿去跟團隊討論,先用下面這張模板把 outcome、計數與價值假設寫清楚。
把 outcome 故事、計數與成本/效益放在同一張表,會讓模型評估變成可討論、可回頭修正的產品決策。
練習
- 選一個你熟悉的預測或分類題目。
- 寫出四種 outcome 的故事版本(各一句話)。
- 每種 outcome 填一個成本/效益(先用粗估也可以)。
- 用這張表跟團隊討論:要更保守,還是更積極?
下面這張圖把「閾值」的取捨畫成兩個版本。它適合用來討論:你要減少 FP 的干擾,還是要避免 FN 漏掉關鍵事件。
同一個模型,閾值不同就會得到不同的風險分佈。把取捨講清楚,才知道要更保守或更積極。
回到 Part 1: 首頁