Lesson 4
Lesson 4 - Digital Twin
先用例子看見 system 的複雜度,再用 digital twin 把資料、狀態、UI 與 AI 推論關係畫成可討論的模型。
例子
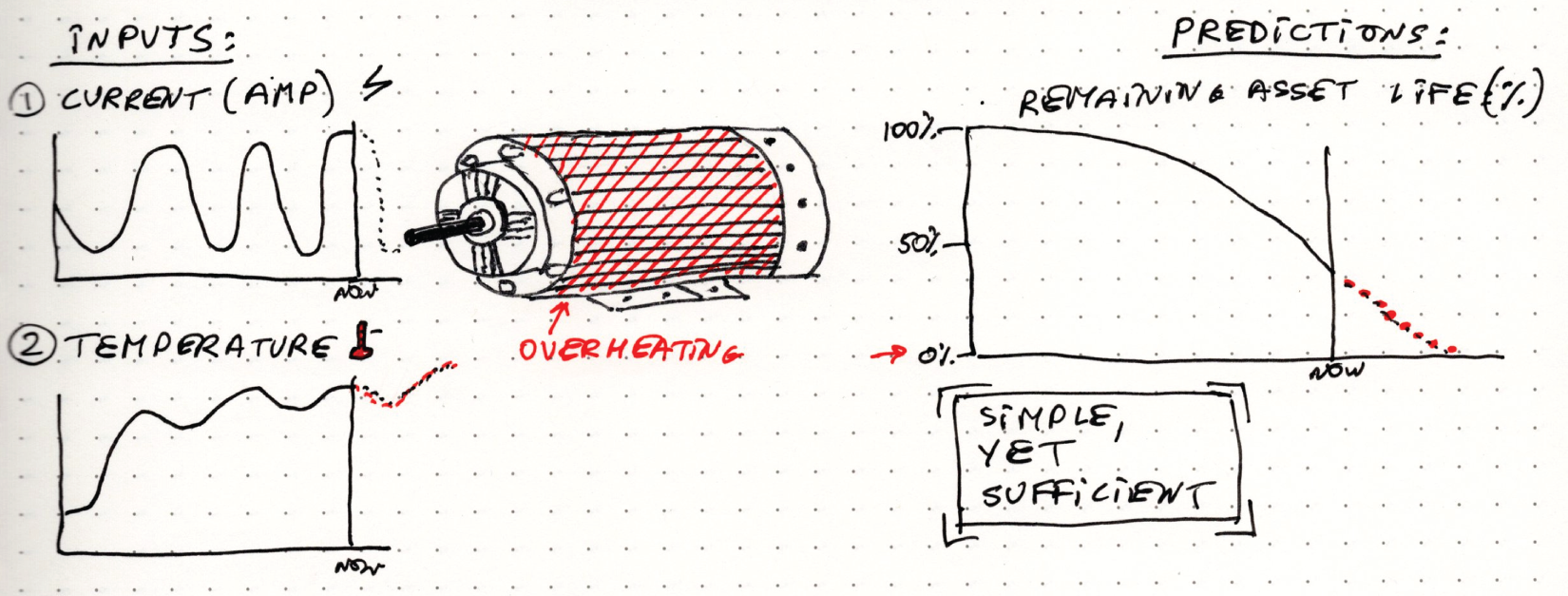 Figure 4.2 Digital twin model diagram
Figure 4.2 Digital twin model diagram 先畫模型:有哪些元件、哪些狀態、哪些資料流。這張圖會決定後面 UI 與 AI 推論要放在哪裡。
Source in book: Chapter 4
圖解(把 UI 與資料對齊)
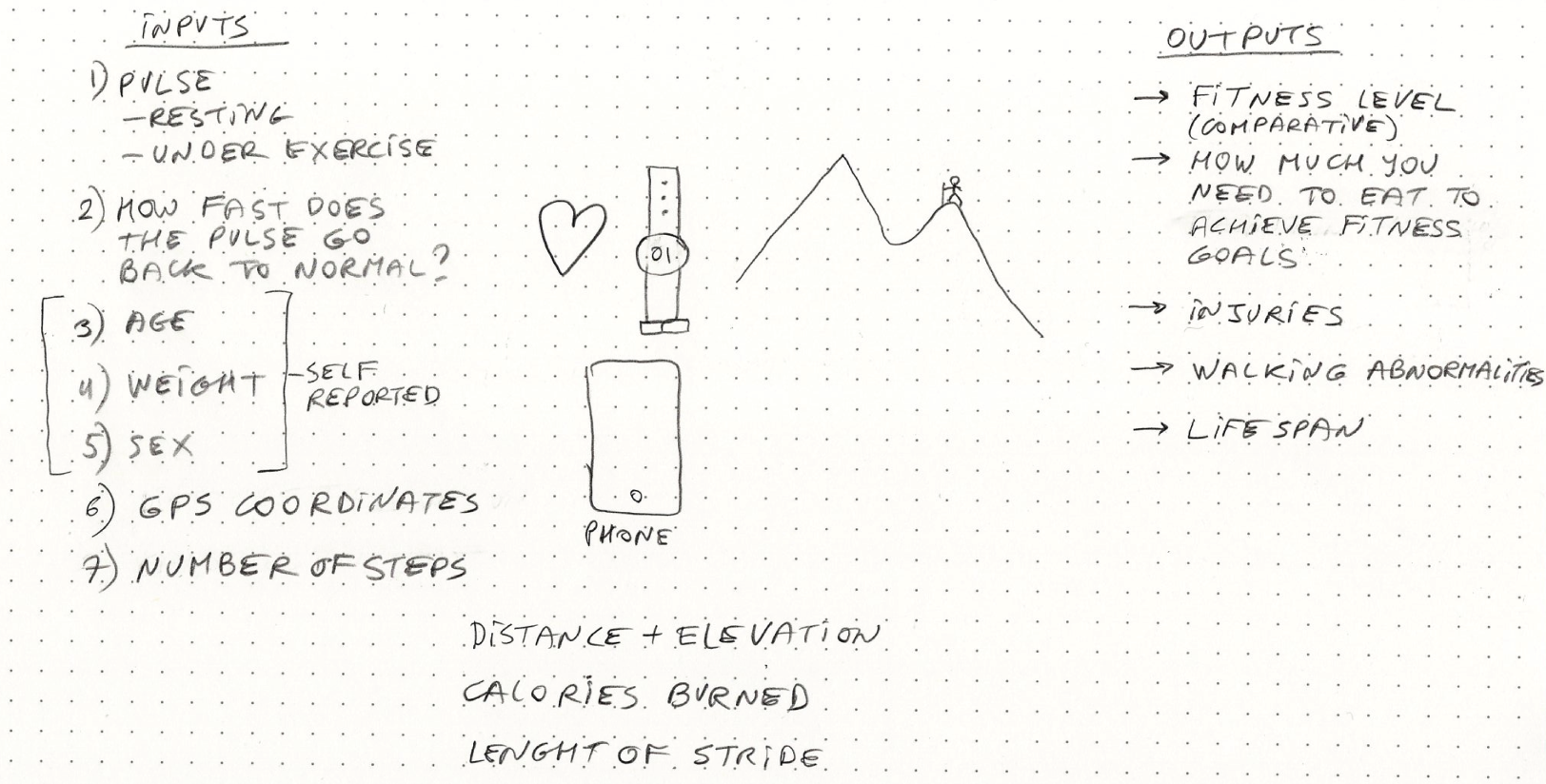 Figure 4.8 Digital twin UI example
Figure 4.8 Digital twin UI example 把模型落到畫面:使用者需要看見哪些狀態?哪些數值需要對照趨勢?哪些資訊是 AI 推論,哪些是原始量測?
Source in book: Chapter 4
 Figure 4.10 Digital twin UI example
Figure 4.10 Digital twin UI example 同一個模型在不同畫面會強調不同資料型態。先把資料型態列清楚,後面的互動設計會更穩。
Source in book: Chapter 4
方法(照原書順序:先建模,再談 AI)
練習
- 選一個你熟悉的系統。
- 先畫一張 digital twin 模型圖(元件 + 狀態 + 資料)。
- 用一個畫面把模型落地:使用者需要看見哪三個狀態?需要哪兩個對照?